
 Google Scholar
Google Scholar
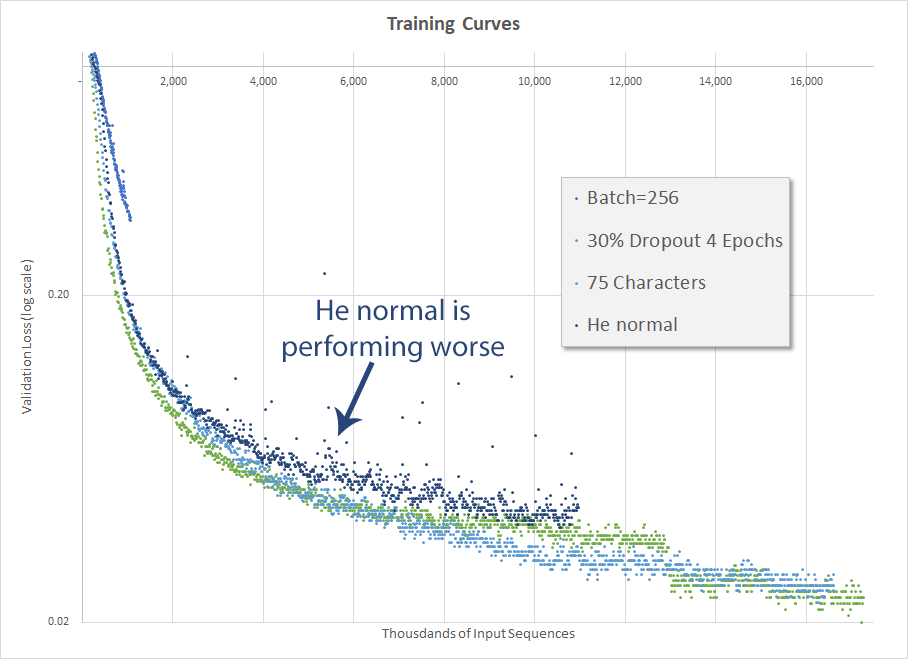
He normal makes things worse
Initializing weights is important
Initializing the weights properly can make the difference between a model that trains nicely and converges to a generalized solution, and one that either explodes, never quite gets there or trains more slowly. The Udacity sequence-to-sequency RNN example used a random uniform initialization (tf.random_uniform_initializer(-0.1, 0.1, seed=2)) for the encoder and decoder and then a truncated normal initialization (tf.truncated_normal_initializer(mean=0.0, stddev=0.1)) for the decoder dense layer, while Weiss used a Gaussian initialization scaled by fan-in, also known as He normal initialization.
Again, the training results were disappointing. Not only did the He normal initialization (achieved via tf.contrib.layers.variance_scaling_initializer() - the default is He normal) not surpass the very basic random uniform initialization, but it performed worse. This is both disappointing and surprising, given that normal initializers typically surpass uniform ones.
This is odd
Also interesting is how, unlike the previous configurations, with the He normal initialization there are a number of validation losses that are significantly outside of the trend. You can see the couple dozen blue dots in the white space above the He normal validation loss curve. I have no explanation or theory for that.
Leave a Comment