
 Google Scholar
Google Scholar
Running on EC2
Even with a local GPU there is a certain convenience to training in the cloud. For starters, you can turn off your machine, which is especially handy if your training takes multiple days (or weeks). If training causes your laptop’s fan to whir, there’s also the benefit to some quiet.
Getting off the ground
The first step is to create an account at AWS. Since I took the Udacity Deep Learning Nanodegree I already had one.
Next, you’ve got to launch an instance on EC2. Here things can get complicated. If you just grab a generic accelerated computing instance, like the g2.2xlarge, you’ll then have to set it up. There are a number of instructional websites on getting things set up, which generally involve installing CUDA, cuDNN, Tensorflow and then whatever else you need, but you can also grab an AMI that already has everything you need. I decided to run with the AMI provided by the Udacity course.
Finally, you need to log into your instance, load up your code, typically accomplished by cloning a Github repo, and then run. If you’re going to be training for any length of time, nohup is your friend. I put a number of helpful commands at the top of the .ipynb file in the Github repo.
Phoning home
One thing which is decidedly inconvenient about running in the cloud is that it’s difficult to know how things are going. You could log into the instance and check an output file, but that can be a hassle. For fun (isn’t all of this fun?) I decided to have my script periodically email me updates. Setting up email on EC2 isn’t too hard, so now at the end of each epoch I get an email like this:
Batch size: 128
RNN size : 512
Num layers: 2
Enc. size : 512
Dec. size : 512
Keep prob.: 0.7
Learn rate: 0.001
Epoch 3/4 Batch 100/32453 Inputs (000) 8320 - Loss: 0.053 - Validation loss: 0.037
Epoch 3/4 Batch 200/32453 Inputs (000) 8333 - Loss: 0.078 - Validation loss: 0.056
Epoch 3/4 Batch 300/32453 Inputs (000) 8346 - Loss: 0.052 - Validation loss: 0.044
Epoch 3/4 Batch 400/32453 Inputs (000) 8359 - Loss: 0.052 - Validation loss: 0.044
Epoch 3/4 Batch 500/32453 Inputs (000) 8371 - Loss: 0.065 - Validation loss: 0.042
...
...
...
Epoch 3/4 Batch 32100/32453 Inputs (000) 12416 - Loss: 0.057 - Validation loss: 0.034
Epoch 3/4 Batch 32200/32453 Inputs (000) 12429 - Loss: 0.046 - Validation loss: 0.036
Epoch 3/4 Batch 32300/32453 Inputs (000) 12442 - Loss: 0.036 - Validation loss: 0.035
Epoch 3/4 Batch 32400/32453 Inputs (000) 12455 - Loss: 0.039 - Validation loss: 0.035
Epoch 3/4 Batch 32453/32453 Inputs (000) 12461 - Loss: 0.041 - Validation loss: 0.035
Model training for 21h:2m:48s and saved.
Current accuracy = 70.4%
I don’t know why, but getting email updates from EC2 on the status of my neural network training has been more thrilling and I would ever have anticipated.
Making it happen
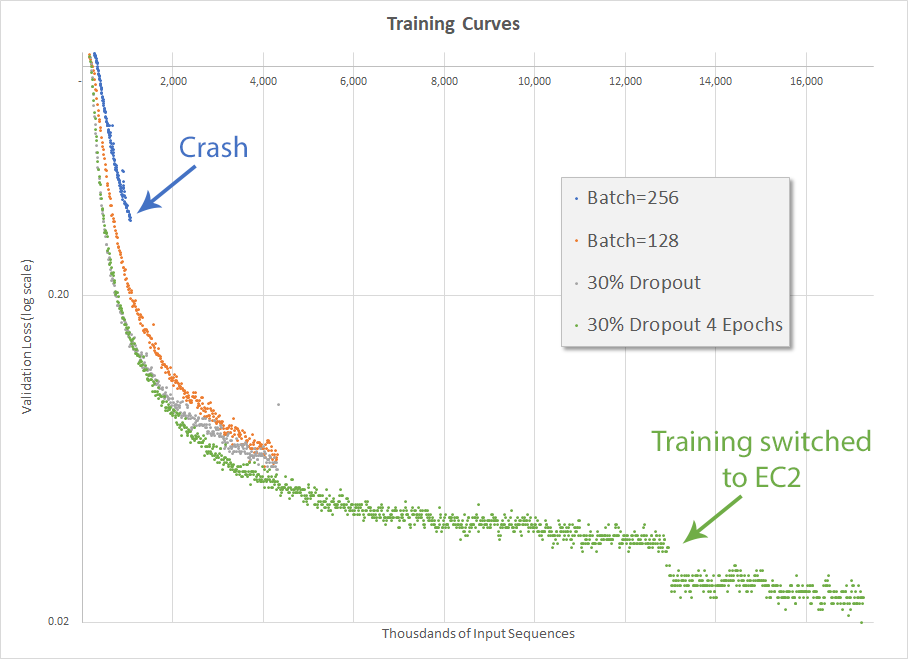
After getting everything set up on EC2, I trained for 3 epochs on my local GPU (using a batch size of 128 and 30% dropout) before transferring the whole thing, minus the source and validation files but including the current state of the graph, into the cloud. The fourth and final epoch was then successfully run on EC2. Yay.
The result below, however, is a bit odd. The discontinuity between the 3rd and 4th epochs is certainly due to the fact the source and validation files were regenerated before training continued. Which leads me to wonder the extent to which the training can be affected by the random sort when generating the source and validation files. It also makes me wonder if any efficiencies can be obtained by generating those files after every epoch, which is not something I have been doing. Those are ideas I will try to explore later.
The final accuracy was 75.1% after over 24 hours of total training. This is quite a bit lower than the goal of 90% after 12 hours, so there is more work to be done.
Leave a Comment