Jekyll2026-04-27T11:57:27-07:00https://mdcramer.github.io/feed/deep-speeling-blog.xmlHackin’ and Tinkerin’ | Deep-speeling-blogA collection of blogs related to some of my work on GitHub and elsewhereMark CramerConclusion2018-10-06T00:00:00-07:002018-10-06T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/conclusionFor a while there, thanks to taking the Udacity Deep Learning Nanodegree, which is what got me hooked on deep learning in the first place, I had a bunch of free usage on AWS. A couple of months ago, however, my pool of free usage ran dry and, even though my instance has been dormant for a long time, I started getting charged ~$4 a month. Certainly not a lot of money, but I haven’t worked on this project is almost a year, so I felt it was time to pull the plug.
Despite all my effort, in the end I was not able to reproduce the results on Tal Weiss’ Deep Spelling blog post; he described getting 95.5% accuracy on the Validation set and I was never able to get much more than 75%. Apparently reproducing other people’s results can be challenging. Dong Wang, a software engineer who used to work at Pinterest, was able to develop a spelling correction RNN that reached 90% accuracy, but he was using a different data set.
The experience, however, was far from being a failure. Not only did I learn a ton from just banging the code together myself and then tweaking an running the models, it was actually a lot of fun. Every time I ran a model it was quite a thrill to watch the numbers come in and see what happened. If my energies weren’t being devoted to a new job and other projects, I might be inclined to continue to push on this.
Update: 17 October 2018 - In April 2018 The Atlantic published an interesting article about how the Scientific Paper is Obsolete. In it, the author had this to say:
“The more sophisticated science becomes, the harder it is to communicate results. Papers today are longer than ever and full of jargon and symbols. They depend on chains of computer programs that generate data, and clean up data, and plot data, and run statistical models on data. These programs tend to be both so sloppily written and so central to the results that it’s contributed to a replication crisis, or put another way, a failure of the paper to perform its most basic task: to report what you’ve actually discovered, clearly enough that someone else can discover it for themselves.”
If the results in scientific papers are difficult to reproduce, it should be no surprise that blog posts on the internet would be even more difficult. For what it’s worth, all of my code and data are available so should anyone who wishes to try to replicate my results encounter difficulty, please let me know.
]]>Mark CramerDropout Experiment with Only Popular Words2017-11-05T00:00:00-07:002017-11-05T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/dropout-experiment-with-only-popular-wordsAs mentioned earlier, I am becoming increasingly skeptical of the possibility of reaching 90% accuracy after 12 hours of training using Mr. Weiss’ methodology and the publicly available billion word dataset released by Google. However, I am a stubborn individual and so I thought I would experiment with adjusting the Regularization to see if that helps.
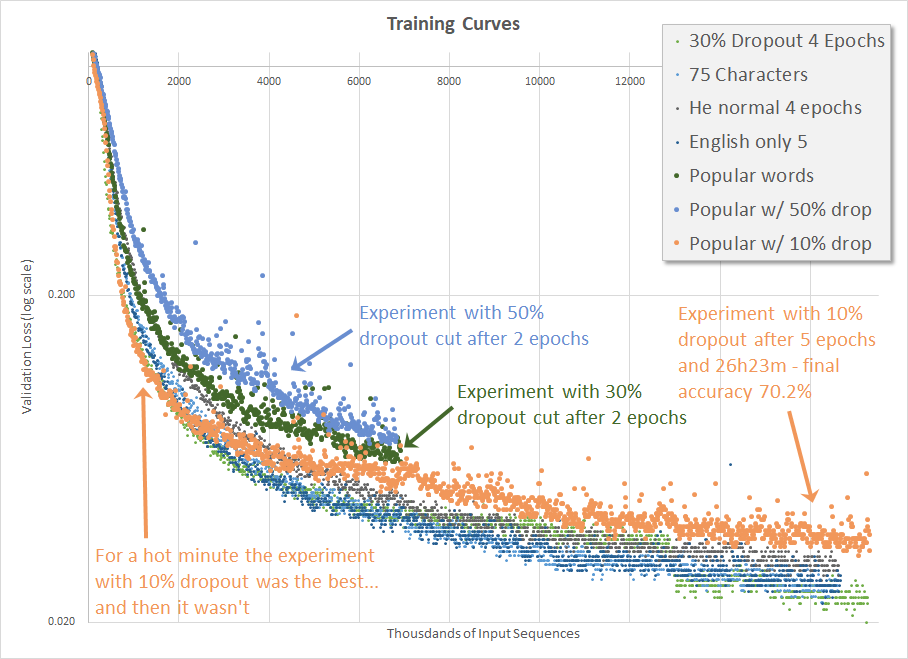
The fact that the previous experiment, where I removed all of the sentences with uncommon words, produced an inferior result makes no sense whatsoever; the problem was significantly simplified and yet the validation results during training were considerably worse. Upon reflection, if the ‘size’ of the problem is reduced and yet the network performs worse, perhaps it is over-fitting.
As such, I decided to adjust the Dropout from the 30% I’ve been using to a more aggressive 50%. (Mr. Weiss’ blog says that he used 30% although his code has 20%, so perhaps it’s worth fudging.) If you’ve been following along you can probably guess that, naturally, the result was yet even worse (below).
Continuing, if increasing the Dropout has a significant negative impact on training, then perhaps reducing it would help. Logically this makes little sense to me, as the scope of the problem was just reduced, but I decided to try nonetheless. I launched the training before heading out for a day at an AI Conference, and things were initially looking great during the first hour before I left the house, but by the time I got home the training went sideways. I decided to run a full 5 epochs just to see how it would finish and at the end I achieve 70.2% accuracy. It should be noted that this is much lower than the 75.1% accuracy achieved prior to implementing He normal initialization, extracting non-English sentences from the dataset and removing sentences with uncommon words and numbers.
Every time I’ve tried to implement an improvement it has degraded the network’s ability to learn. I’m again not quite sure where to go from here. Perhaps I’ll dig deeper into the dataset or perhaps I should build the RNN using Keras, just in case something is implemented differently there.
Continuing with the dataset that contains only popular words, adjusting the Dropout produces an effect, but does not improve the results significantly enough.]]>Mark CramerEliminating Uncommon Words Makes Things Worse2017-11-03T00:00:00-07:002017-11-05T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/eliminating-uncommon-words-makes-things-worseThis is frustrating.
In the quest for 90% accuracy I decided to take another look at Mr. Weiss’ code and noticed that in preprocesses_split_lines4() he is “… selecting only sentences with most-common words.” The call to the function is commented out, and more than half of the function is commented out as well (it appears to be using word2vec, but I’m not seeing how), but it got me to thinking:
Perhaps this ‘problem’ can be simplified by removing sentences with very uncommon words, such as those that only ever appear once. It’s unreasonable to think that a neural network could ‘know’ how to spell a word without ever seeing it previously. Those very uncommon words probably contain many proper names and misspellings (which I should check at some point).
Additionally, while I’m at it, the problem could potentially be simplified even further by removing sentences with numbers. How would a human being, let alone a neural network, know that “I have 41 apples” was, in fact, a transposition of “I have 14 apples.”
Therefore, after stripping out all digits and punctuation, I created a frequency dictionary of every ‘word’ in the dataset (“don’t” gets represented as “dont”, which is fine, and “egg-beater” becomes “eggbeater”, which is arguably better) and then removed all sentences containing a ‘word’ that only appears once (i.e. a unique word). Additionally, I removed any sentence containing digits. (This process, by the way, took 30 hours to run.)
While previously my dataset has 4,161,772 lines, the new one has only 3,463,951 lines, for a reduction of 20%, which seems pretty sizable. As such, I was giddily anticipating a considerable improvement in accuracy. Naturally, as has been my experience so far, the outcome (below) was exactly the opposite.
How is this possible? How can removing the obviously difficult ‘words’ to spell from the dataset result in a significantly worse outcome when training. For the moment, I don’t even have a theory as to what might have happened here.
Removing sentences with uncommon words from the dataset significantly reduces training performance.]]>Mark CramerReducing the Validation and Test datasets2017-10-20T00:00:00-07:002017-10-23T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/reducing-the-validation-and-test-datasetsBefore starting the process of training, it is common practice to first randomly select a portion of the data to set aside for testing after training is complete. Then it is common practice to randomly select a portion of the remaining data for validation during training. The percentages used to split the data will generally be a function of the amount of data available and the complexity of the model.
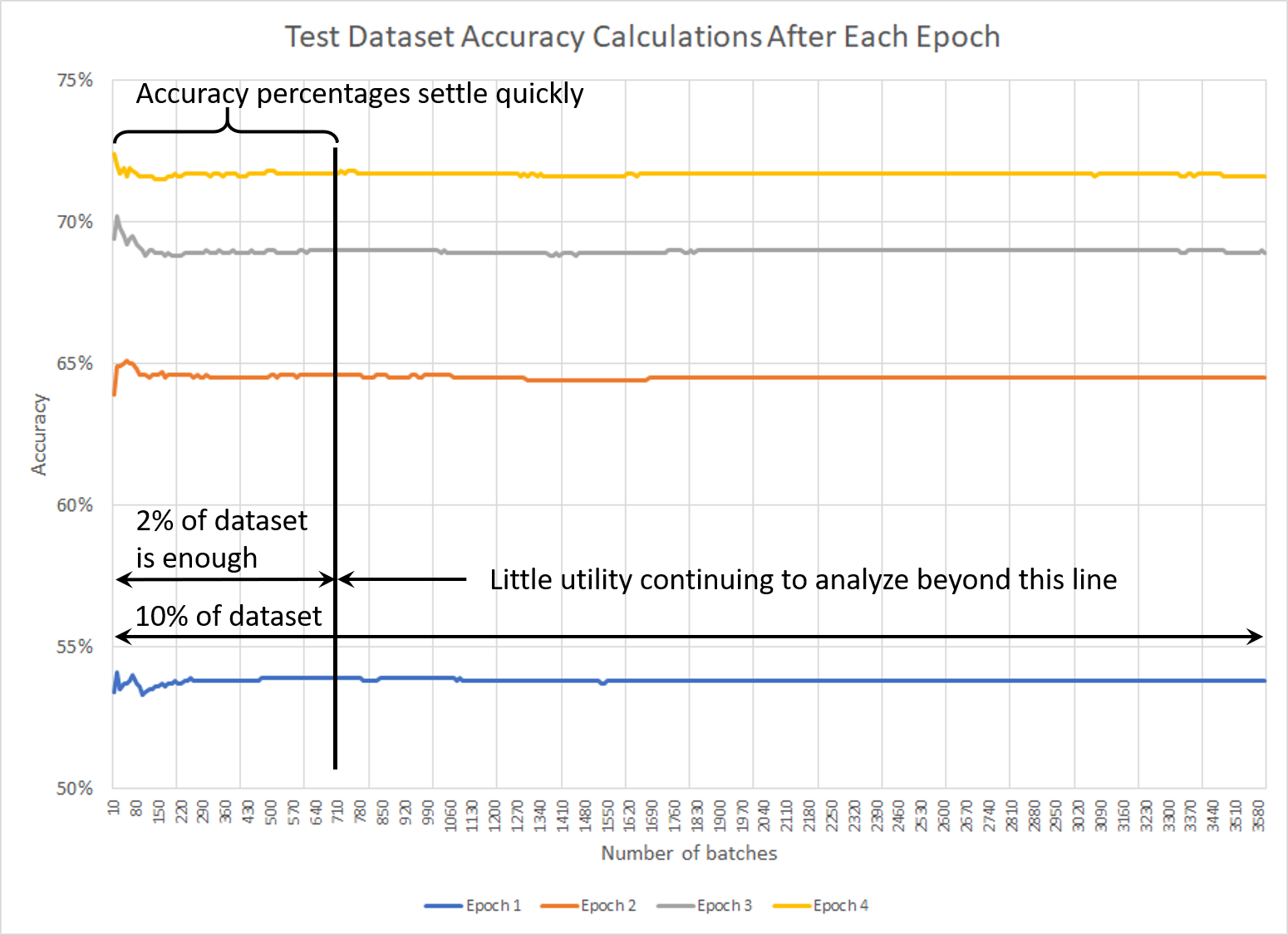
Out of habit, I chose to slice off 10% of the data to set aside for the Test dataset. When analyzing accuracy after each epoch, however, I began to notice that the accuracy percentages converged on a relatively stable determination long before the I finished running the Test dataset (see below). This seemed like a watch of both data and time, given that it took ~30 minutes to run the Test dataset. After consulting my colleagues at CrossValidated, I decided to drop the amount of data set aside for the Test dataset from 10% to 2%. (The same thing could conceivably be done with the Validation dataset used during training, but I’ve been using a single batch for that.)
The result: A little more data for training and a little less time spend computing accuracy after each epoch. Meh, but why not?
Extensive evaluation of Test dataset does not appreciable improve the determination of accuracy after a certain point.]]>Mark CramerNo hablo español2017-10-16T00:00:00-07:002017-10-16T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/no-hablo-espanolAs mentioned at the beginning, the first goal is to reproduce the results produced by Mr. Weiss. After implementing virtually everything in his post, including the He normal initialization, and building a highly similar model, the target of 90% accuracy (let alone 95.5%) is proving elusive.
I am thus going to start branching out.
Removing non-English sentences from the dataset
It is critical to know the data set. It is also critical to clean the dataset, which is what data scientists spend most of their time doing.
Since the inception of this project I’ve been peaking into the and have noticed, despite the “.en” in the source filename, a considerable number of non-English sentences, like Toujours aussi inconstant, le Brésil, tombé au 19e rang du classement FIFA, a certes réagi après l'ouverture du score de la tête de Gonzalez (7). While I would imagine that a neural network could be trained to simultaneously correct spelling for multiple different languages, this will only increase the complexity of the problem. Additionally, only a smattering of different languages is going to be nothing more than noise. Thus, I’ve decided to scrub the data set of anything non-English.
Using langdetect I constructed a routine to iterate through the entire file and remove any sentences that were not identified as English. In the process, I discovered a few things about langdetect:
It is not entirely accurate. Sentences like You made it home! return “fr”. To mitigate this effect I used detect_langs, which returns a probability distribution of possible languages, and accept anything that has a non-zero chance of being English.
It is not consistent. Repeatedly processing Hello, I'm christiane amanpour. returned [it:0.8571401485770536, en:0.14285811674731527] then [it:0.8571403121803622, fr:0.14285888197332486] and then [it:0.999995562246093], all of which are incorrect, by the way. (It’s unclear why “Christiane Amanpour” isn’t capitalized, but that’s the way it is in the source file.)
It throws an error when processing text it cannot “identify,” such as URLs and emails. This actually turns out to be a happy result since things like http://abcn.ws/11JABPu and rswilloughby@pomlaw.com are not going to help much with training, so it’s good to get rid of them anyway.
It is slow. It took 24 hours to process 21,688,362 lines, which works out to about 250 lines a second. I guess that’s not too bad.
Perhaps my next project should be to build a language detection neural network. I digress.
In any event, the end result is that 848,326 lines, including 345 “errors,” were removed from the source file. That’s only 3.9% of the lines, however, after further processing to remove sentences that contain characters outside the top 75, the size of the source dataset dropped from 4,154,135 lines to 3,793,771, which is a reduction of 8.7%.
That’s the theory, anyway
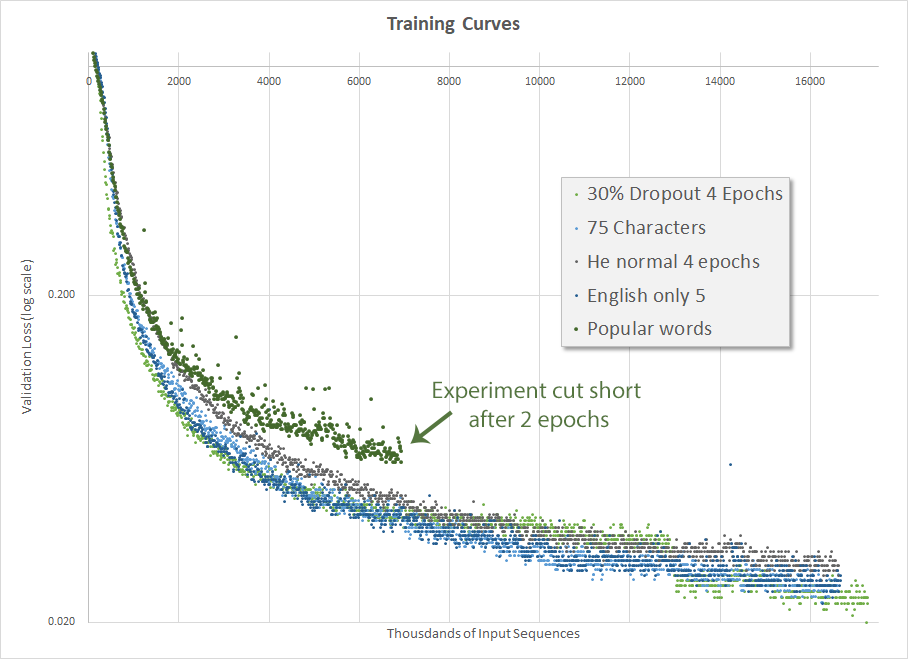
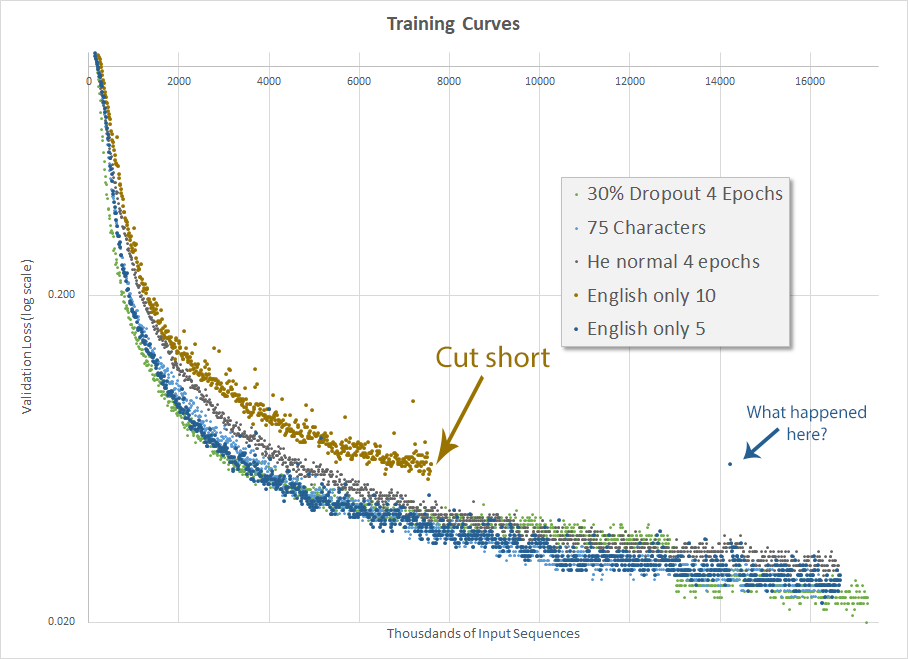
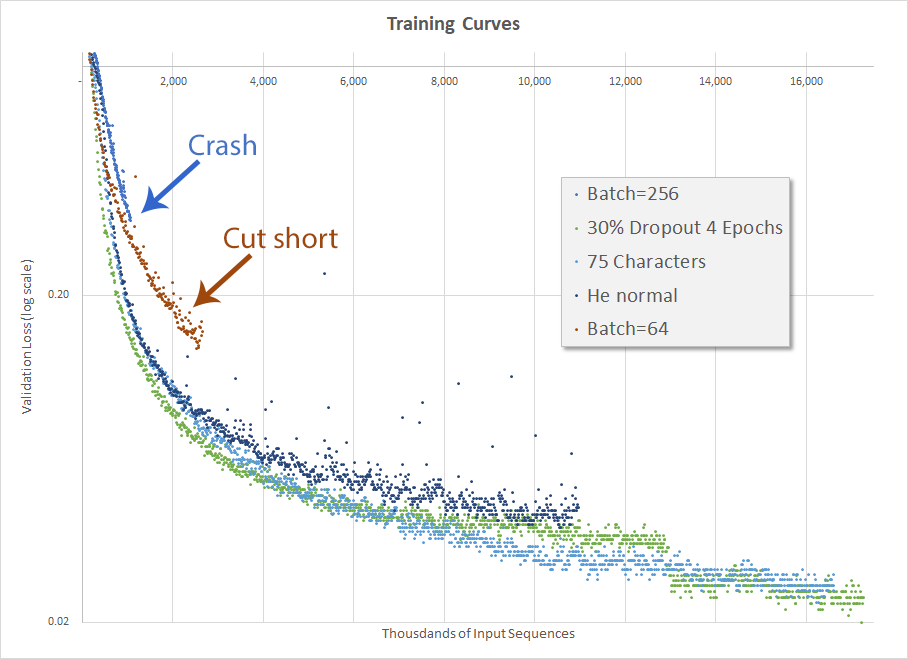
The actual result, after two days of training, is disappointing. In my first run (orange-brown dots) I inadvertently also changed the minimum input size from 5 to 10, which had a pretty negative impact on training so I cut it short. It’s often helpful to not change multiple things at the same time.
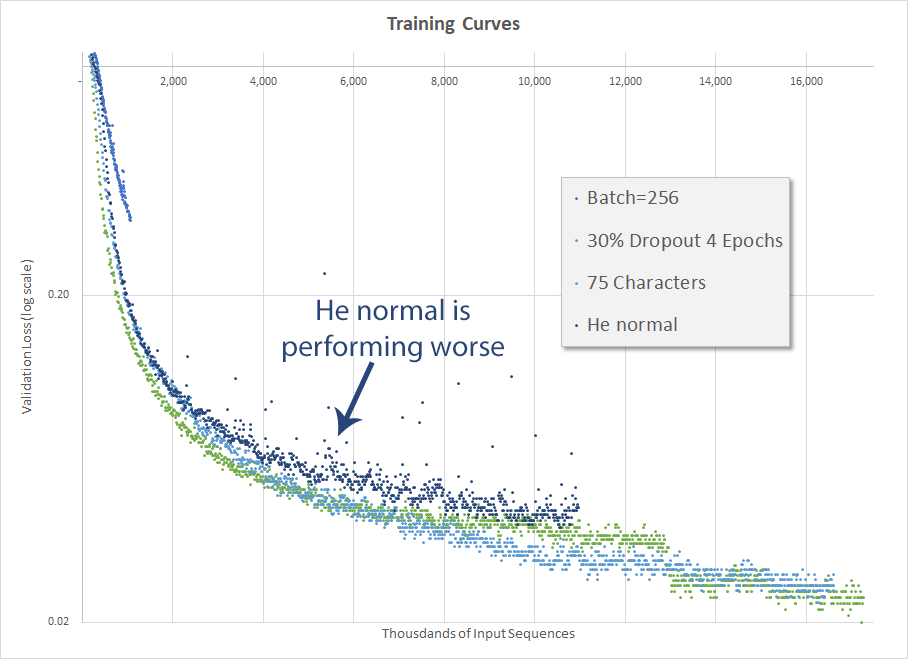
The second run (dark blue dots) actually did well, although not better than the run a couple weeks ago when I changed the number of allowable characters from 100 to 75 and before I implemented He normal initialization. The final validation accuracy was 70.0%. This is another disappointing result and I continued to be perplexed as to how Mr. Weiss got to 95.5% accuracy.
I have not yet, however, run out of ideas.
Validation loss for various hyperparameter configurations]]>Mark CramerHe normal makes things worse2017-10-01T00:00:00-07:002017-10-07T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/he-normal-makes-things-worseInitializing weights is important
Initializing the weights properly can make the difference between a model that trains nicely and converges to a generalized solution, and one that either explodes, never quite gets there or trains more slowly. The Udacity sequence-to-sequency RNN example used a random uniform initialization (tf.random_uniform_initializer(-0.1, 0.1, seed=2)) for the encoder and decoder and then a truncated normal initialization (tf.truncated_normal_initializer(mean=0.0, stddev=0.1)) for the decoder dense layer, while Weiss used a Gaussian initialization scaled by fan-in, also known as He normal initialization.
Again, the training results were disappointing. Not only did the He normal initialization (achieved via tf.contrib.layers.variance_scaling_initializer() - the default is He normal) not surpass the very basic random uniform initialization, but it performed worse. This is both disappointing and surprising, given that normal initializers typically surpass uniform ones.
This is odd
Also interesting is how, unlike the previous configurations, with the He normal initialization there are a number of validation losses that are significantly outside of the trend. You can see the couple dozen blue dots in the white space above the He normal validation loss curve. I have no explanation or theory for that.
Validation loss for various hyperparameter configurations]]>Mark CramerGoldilocks batch size2017-10-01T00:00:00-07:002017-10-04T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/goldilocks-batch-sizeBatch size of 64 is too small
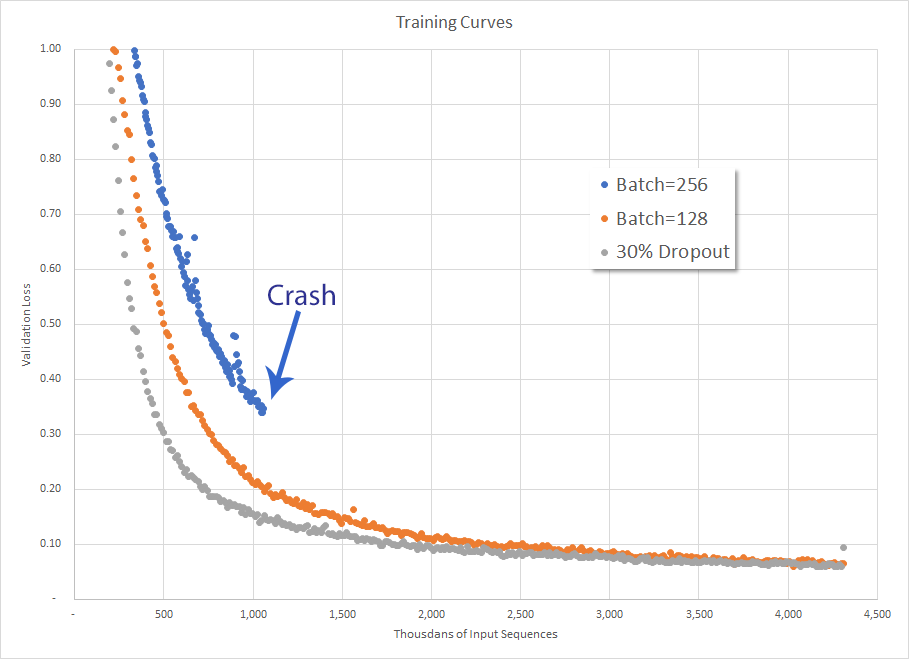
As we learned in a previous post, a batch size of 256 is too large. Since then I’ve been running with a batch size of 128 when I got to thinking, if 128 is better than 256 then perhaps 64 is even better than that.
It is not.
For whatever reason, training with a batch size of 64 progressed significantly slower than all of the training with a batch size of 128. It was so poor that I cut it off before even completing the first epoch. I’ll be going back to 128 now because, apparently, that one is “just right.”
Validation loss for various hyperparameter configurations]]>Mark CramerRunning on EC22017-09-27T00:00:00-07:002017-10-16T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/running-on-ec2Even with a local GPU there is a certain convenience to training in the cloud. For starters, you can turn off your machine, which is especially handy if your training takes multiple days (or weeks). If training causes your laptop’s fan to whir, there’s also the benefit to some quiet.
Next, you’ve got to launch an instance on EC2. Here things can get complicated. If you just grab a generic accelerated computing instance, like the g2.2xlarge, you’ll then have to set it up. There are a number of instructional websites on getting things set up, which generally involve installing CUDA, cuDNN, Tensorflow and then whatever else you need, but you can also grab an AMI that already has everything you need. I decided to run with the AMI provided by the Udacity course.
Finally, you need to log into your instance, load up your code, typically accomplished by cloning a Github repo, and then run. If you’re going to be training for any length of time, nohup is your friend. I put a number of helpful commands at the top of the .ipynb file in the Github repo.
Phoning home
One thing which is decidedly inconvenient about running in the cloud is that it’s difficult to know how things are going. You could log into the instance and check an output file, but that can be a hassle. For fun (isn’t all of this fun?) I decided to have my script periodically email me updates. Setting up email on EC2 isn’t too hard, so now at the end of each epoch I get an email like this:
I don’t know why, but getting email updates from EC2 on the status of my neural network training has been more thrilling and I would ever have anticipated.
Making it happen
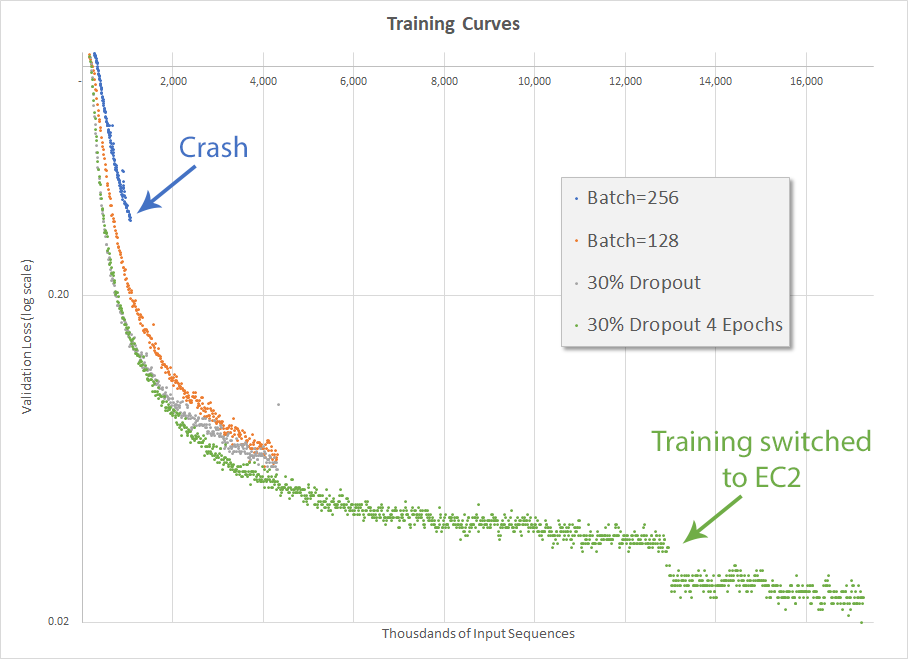
After getting everything set up on EC2, I trained for 3 epochs on my local GPU (using a batch size of 128 and 30% dropout) before transferring the whole thing, minus the source and validation files but including the current state of the graph, into the cloud. The fourth and final epoch was then successfully run on EC2. Yay.
The result below, however, is a bit odd. The discontinuity between the 3rd and 4th epochs is certainly due to the fact the source and validation files were regenerated before training continued. Which leads me to wonder the extent to which the training can be affected by the random sort when generating the source and validation files. It also makes me wonder if any efficiencies can be obtained by generating those files after every epoch, which is not something I have been doing. Those are ideas I will try to explore later.
The final accuracy was 75.1% after over 24 hours of total training. This is quite a bit lower than the goal of 90% after 12 hours, so there is more work to be done.
Validation loss for various hyperparameter configurations]]>Mark CramerSaving for future training2017-09-24T00:00:00-07:002017-10-07T00:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/saving-for-future-trainingThe Udacity sequence to sequence project that I used as a starting point for the code actually had code to save and then reload the graph. I’m not sure why they decided to do that, but the graph is saved at the end of training and then reloaded right before it is used to make a prediction. So simply going back to continue training after the graph is saved should be easy, right?
Nothing is ever easy.
Getting help from Stack Overflow
The problem was that while the Udacity project saved the graph, it only ‘named’ those variables necessary for the predictions. It did not ‘name’ those variables that are also necessary for continued training. This problem vexed me for days, so I finally went to Stack Overflow for assistance. While there were a number of generous individuals who tried to give me a hand, in the end I had to figure it out myself. For the benefit of others who might stumble across the same problem, I went ahead and answered my own question.
Setting up the script to run automatically.
While I was fiddling with the script I figured I would also get the thing to run ‘automatically’ from top to bottom. Part of the problem with Jupyter (or perhaps one of the benefits of Jupyter), is that you can manually execute the cells one at a time. When doing so it’s easy to jump over any cells that shouldn’t be run, for whatever reason.
Therefore, I arranged the code so that not only could it run from top to bottom automatically, but I could export the script to a .py file and run it from the command line. This will be handy for running in the background on EC2. Additionally, I added the ability to insert the command line switch “small” to indicate that the script should run on the small data. This turns out to be very handy for testing and debugging.
]]>Mark CramerSmaller batches and Dropout2017-09-16T00:00:00-07:002017-10-06T17:00:00-07:00https://mdcramer.github.io/deep-speeling-blog/smaller-batches-and-dropoutBatch size of 256 is too large
I used a batch size of 256 during my first crack at training the RNN and, as can be seen below, it crashed before completing the first epoch. I’m not sure how long it took to get to that point, but it was probably only a couple hours in.
Adding Dropout
Not only did dropping the batch size down to 128 improve training performance (the validation loss came down more quickly), but the RNN was able to successfully train for 6 hours on my local machine. That being said, it’s generally a good idea to use some form of Regularization to prevent over-fitting. The Udacity project didn’t have any Regularization, so I added 30% Dropout. This had the happy effect of initially increasing the rate at which the validation loss dropped, but at the end of the epoch it was still about the same without dropout.
The spelling correction is also not working particularly well. As an example, “he had dated forI much of the past” becomes “Sou had teap for much to heads tap”. There’s obviously more work to be done.
Validation loss for various hyperparameter configurations]]>Mark Cramer