
 Google Scholar
Google Scholar
Eliminating Uncommon Words Makes Things Worse
This is frustrating.
In the quest for 90% accuracy I decided to take another look at Mr. Weiss’ code and noticed that in preprocesses_split_lines4() he is “… selecting only sentences with most-common words.” The call to the function is commented out, and more than half of the function is commented out as well (it appears to be using word2vec, but I’m not seeing how), but it got me to thinking:
- Perhaps this ‘problem’ can be simplified by removing sentences with very uncommon words, such as those that only ever appear once. It’s unreasonable to think that a neural network could ‘know’ how to spell a word without ever seeing it previously. Those very uncommon words probably contain many proper names and misspellings (which I should check at some point).
- Additionally, while I’m at it, the problem could potentially be simplified even further by removing sentences with numbers. How would a human being, let alone a neural network, know that “I have 41 apples” was, in fact, a transposition of “I have 14 apples.”
Therefore, after stripping out all digits and punctuation, I created a frequency dictionary of every ‘word’ in the dataset (“don’t” gets represented as “dont”, which is fine, and “egg-beater” becomes “eggbeater”, which is arguably better) and then removed all sentences containing a ‘word’ that only appears once (i.e. a unique word). Additionally, I removed any sentence containing digits. (This process, by the way, took 30 hours to run.)
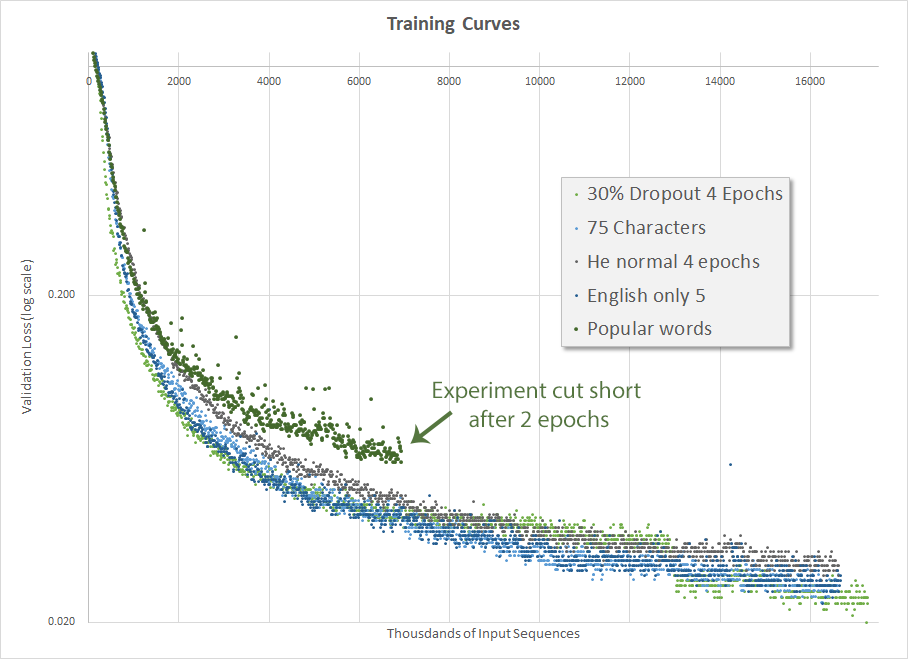
While previously my dataset has 4,161,772 lines, the new one has only 3,463,951 lines, for a reduction of 20%, which seems pretty sizable. As such, I was giddily anticipating a considerable improvement in accuracy. Naturally, as has been my experience so far, the outcome (below) was exactly the opposite.
How is this possible? How can removing the obviously difficult ‘words’ to spell from the dataset result in a significantly worse outcome when training. For the moment, I don’t even have a theory as to what might have happened here.
Leave a Comment