
 Google Scholar
Google Scholar
No hablo español
As mentioned at the beginning, the first goal is to reproduce the results produced by Mr. Weiss. After implementing virtually everything in his post, including the He normal initialization, and building a highly similar model, the target of 90% accuracy (let alone 95.5%) is proving elusive.
I am thus going to start branching out.
Removing non-English sentences from the dataset
It is critical to know the data set. It is also critical to clean the dataset, which is what data scientists spend most of their time doing.
Since the inception of this project I’ve been peaking into the and have noticed, despite the “.en” in the source filename, a considerable number of non-English sentences, like Toujours aussi inconstant, le Brésil, tombé au 19e rang du classement FIFA, a certes réagi après l'ouverture du score de la tête de Gonzalez (7). While I would imagine that a neural network could be trained to simultaneously correct spelling for multiple different languages, this will only increase the complexity of the problem. Additionally, only a smattering of different languages is going to be nothing more than noise. Thus, I’ve decided to scrub the data set of anything non-English.
Using langdetect I constructed a routine to iterate through the entire file and remove any sentences that were not identified as English. In the process, I discovered a few things about langdetect:
- It is not entirely accurate. Sentences like
You made it home!return “fr”. To mitigate this effect I useddetect_langs, which returns a probability distribution of possible languages, and accept anything that has a non-zero chance of being English. - It is not consistent. Repeatedly processing
Hello, I'm christiane amanpour.returned[it:0.8571401485770536, en:0.14285811674731527]then[it:0.8571403121803622, fr:0.14285888197332486]and then[it:0.999995562246093], all of which are incorrect, by the way. (It’s unclear why “Christiane Amanpour” isn’t capitalized, but that’s the way it is in the source file.) - It throws an error when processing text it cannot “identify,” such as URLs and emails. This actually turns out to be a happy result since things like
http://abcn.ws/11JABPuandrswilloughby@pomlaw.comare not going to help much with training, so it’s good to get rid of them anyway. - It is slow. It took 24 hours to process 21,688,362 lines, which works out to about 250 lines a second. I guess that’s not too bad.
Perhaps my next project should be to build a language detection neural network. I digress.
In any event, the end result is that 848,326 lines, including 345 “errors,” were removed from the source file. That’s only 3.9% of the lines, however, after further processing to remove sentences that contain characters outside the top 75, the size of the source dataset dropped from 4,154,135 lines to 3,793,771, which is a reduction of 8.7%.
That’s the theory, anyway
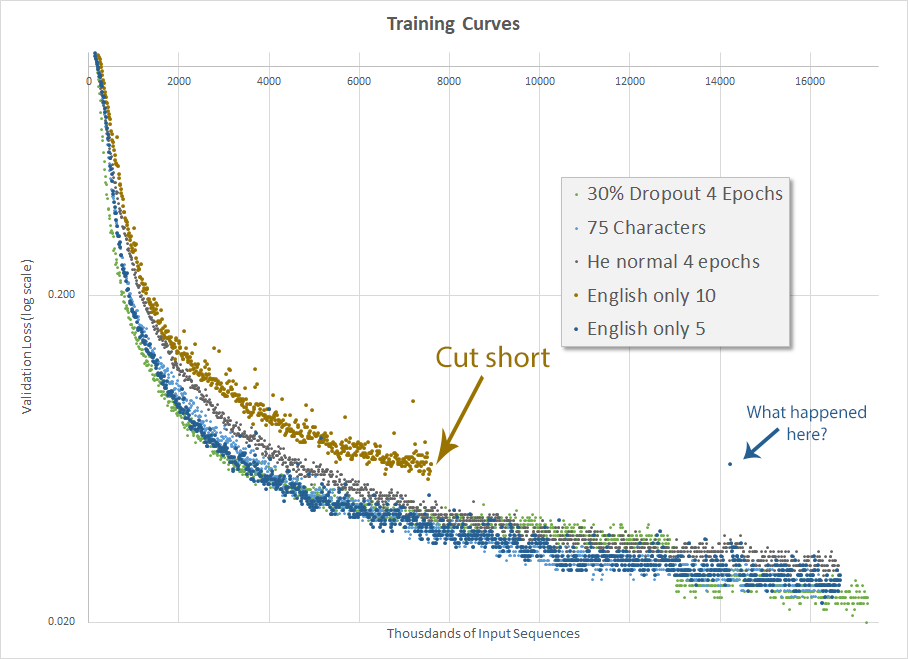
The actual result, after two days of training, is disappointing. In my first run (orange-brown dots) I inadvertently also changed the minimum input size from 5 to 10, which had a pretty negative impact on training so I cut it short. It’s often helpful to not change multiple things at the same time.
The second run (dark blue dots) actually did well, although not better than the run a couple weeks ago when I changed the number of allowable characters from 100 to 75 and before I implemented He normal initialization. The final validation accuracy was 70.0%. This is another disappointing result and I continued to be perplexed as to how Mr. Weiss got to 95.5% accuracy.
I have not yet, however, run out of ideas.
Leave a Comment