
 Google Scholar
Google Scholar
Reducing the Validation and Test datasets
Before starting the process of training, it is common practice to first randomly select a portion of the data to set aside for testing after training is complete. Then it is common practice to randomly select a portion of the remaining data for validation during training. The percentages used to split the data will generally be a function of the amount of data available and the complexity of the model.
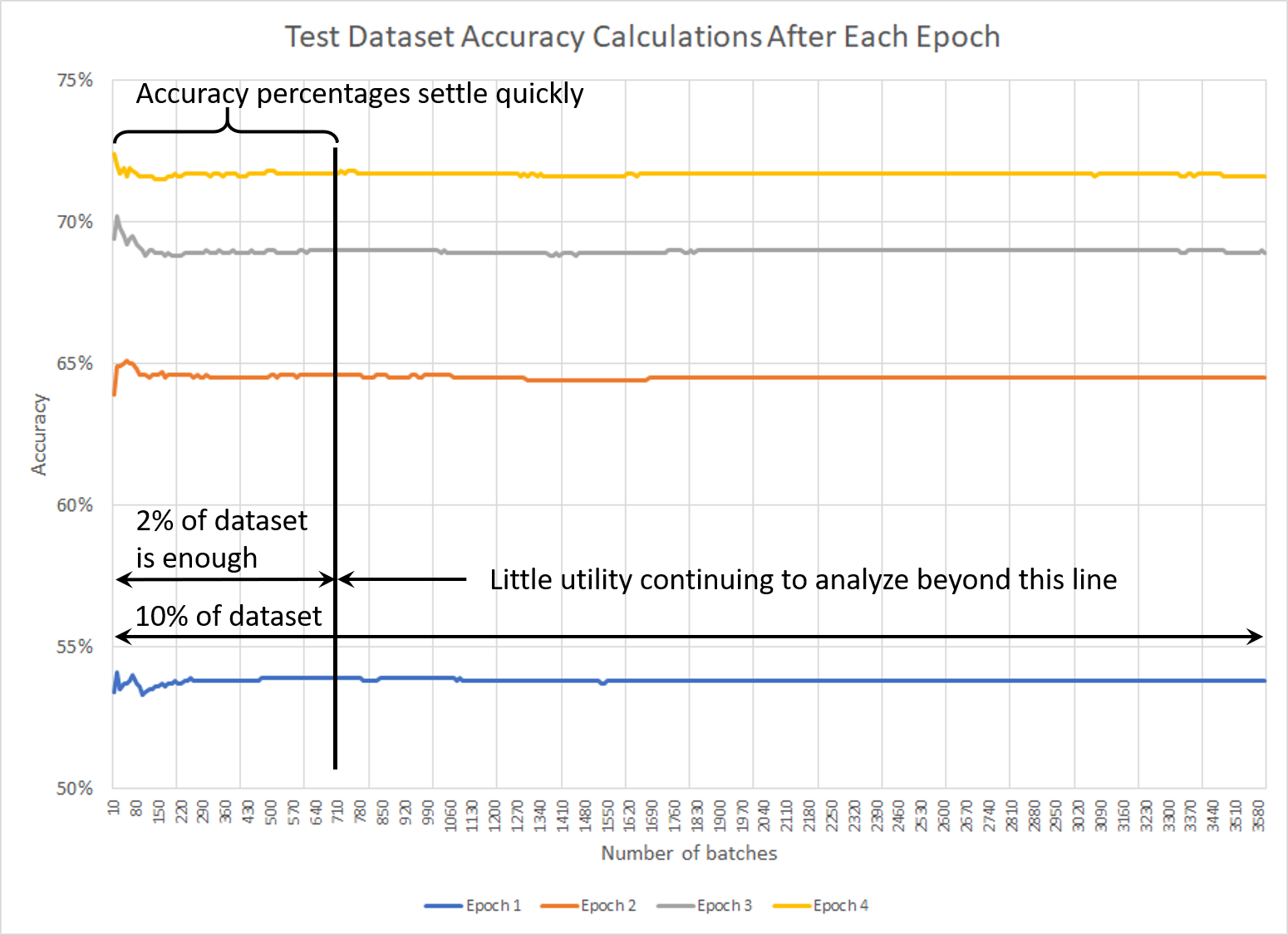
Out of habit, I chose to slice off 10% of the data to set aside for the Test dataset. When analyzing accuracy after each epoch, however, I began to notice that the accuracy percentages converged on a relatively stable determination long before the I finished running the Test dataset (see below). This seemed like a watch of both data and time, given that it took ~30 minutes to run the Test dataset. After consulting my colleagues at CrossValidated, I decided to drop the amount of data set aside for the Test dataset from 10% to 2%. (The same thing could conceivably be done with the Validation dataset used during training, but I’ve been using a single batch for that.)
The result: A little more data for training and a little less time spend computing accuracy after each epoch. Meh, but why not?
Leave a Comment