
 Google Scholar
Google Scholar
Dropout Experiment with Only Popular Words
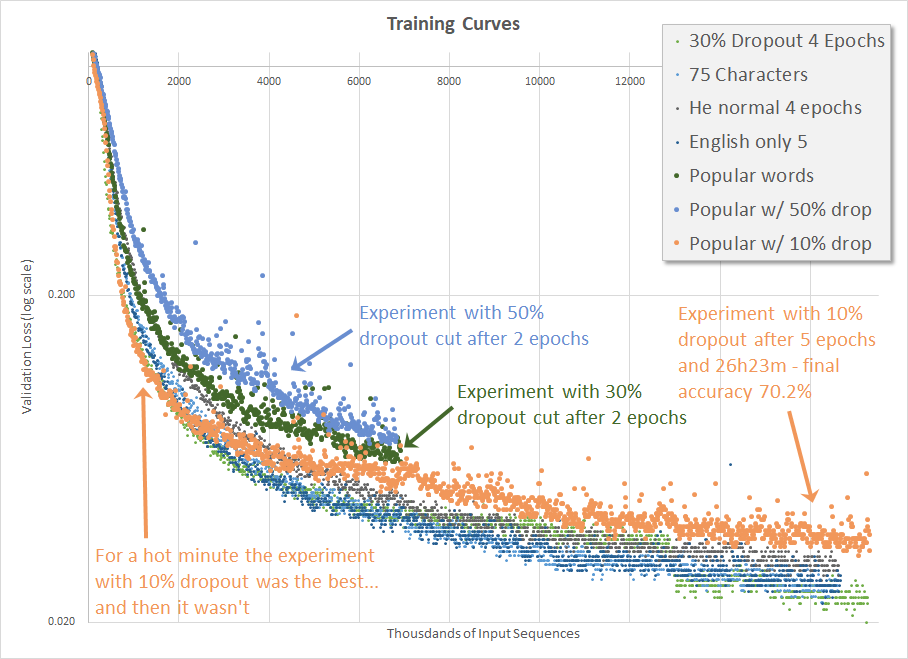
As mentioned earlier, I am becoming increasingly skeptical of the possibility of reaching 90% accuracy after 12 hours of training using Mr. Weiss’ methodology and the publicly available billion word dataset released by Google. However, I am a stubborn individual and so I thought I would experiment with adjusting the Regularization to see if that helps.
The fact that the previous experiment, where I removed all of the sentences with uncommon words, produced an inferior result makes no sense whatsoever; the problem was significantly simplified and yet the validation results during training were considerably worse. Upon reflection, if the ‘size’ of the problem is reduced and yet the network performs worse, perhaps it is over-fitting.
As such, I decided to adjust the Dropout from the 30% I’ve been using to a more aggressive 50%. (Mr. Weiss’ blog says that he used 30% although his code has 20%, so perhaps it’s worth fudging.) If you’ve been following along you can probably guess that, naturally, the result was yet even worse (below).
Continuing, if increasing the Dropout has a significant negative impact on training, then perhaps reducing it would help. Logically this makes little sense to me, as the scope of the problem was just reduced, but I decided to try nonetheless. I launched the training before heading out for a day at an AI Conference, and things were initially looking great during the first hour before I left the house, but by the time I got home the training went sideways. I decided to run a full 5 epochs just to see how it would finish and at the end I achieve 70.2% accuracy. It should be noted that this is much lower than the 75.1% accuracy achieved prior to implementing He normal initialization, extracting non-English sentences from the dataset and removing sentences with uncommon words and numbers.
Every time I’ve tried to implement an improvement it has degraded the network’s ability to learn. I’m again not quite sure where to go from here. Perhaps I’ll dig deeper into the dataset or perhaps I should build the RNN using Keras, just in case something is implemented differently there.
Leave a Comment